I am testing changes to my frontend framework, Places.js that allow creating components without shadow DOM. Previously, all Places.js components had to be created with shadow DOM that required styles to be encapsulated.
In addition to improving flexibility, these changes give another option to optimize rendering performance and make the development experience closer to working with vanilla frontend tools. I want Places.js development to be easy to pick up for anyone familiar with CSS, HTML, and JavaScript.
The changes involved removing code from Places.js. Places.js already has a BaseTemplateComponent class that can be extended to enable shadow DOM components.
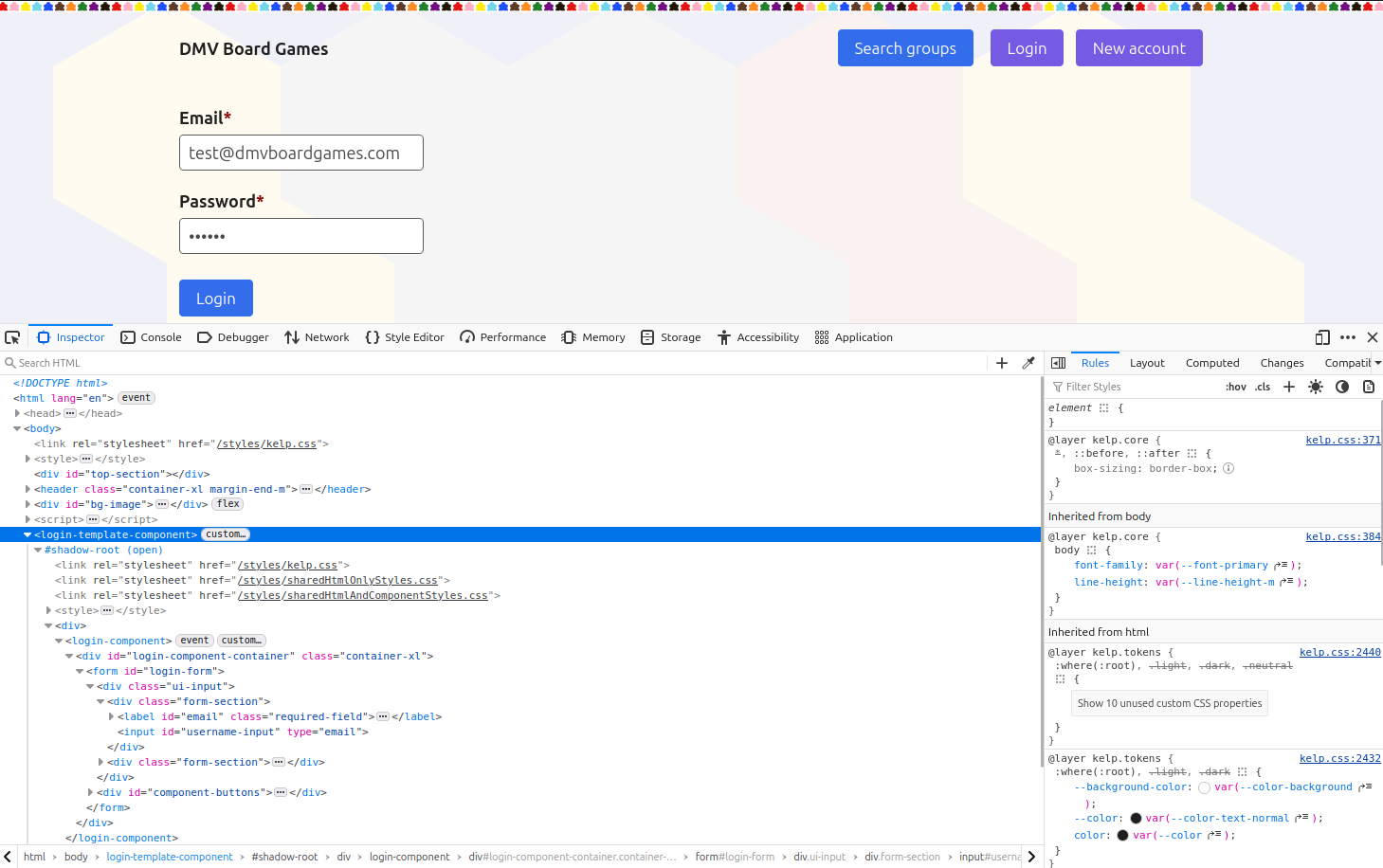
Here is an example of what a login component looks like inside shadow DOM.
I am in the process of moving CSS styles out of the shadow DOM for dmvboardgames.com. My goal is to make my frontend code easier to follow for people familiar with CSS, HTML, and Javascript. While there are benefits to placing HTML in shadow DOM, styling the HTML works differently.
Using the CSS @scope rule, limiting styles to specific web component is straighforward.
Here is an example showing how I scoped styles for the web component that lists event search results. These are the exact same styles that were previously in the shadow DOM.
Aside from concerns about the social and quality impacts of using LLM, I think using LLMs is risky. I don’t see LLMs a useful technology. However. even if I am wrong, I think it makes sense to avoid using them right now.
In a hypothetical world where LLMs turn out to be a useful technology, I see several issues with trying to use them.
1. Rapid Change
LLM technology is rapidly changing, and a high rate of change will continue as businesses invest more money into updating the tools. As a result, the functionality of LLM tools such as Claude or ChatGPT will continue to evolve and skills with using one tool may not translate. The impact of these updates will also cause significant changes to the economy.
Due to the rapid changes, I think it will sense to develop skills outside of LLM use that are more likely to remain relevant.
2. Ensuring that technology has a positive impact
As LLMs become more powerful, their ability to cause significant negative and positive impact will increase. Mitigating these impacts will require people to maintain high-trust societies where people work together to develop and test LLMs. Building trust requires people to get to know each other without LLM chatbots getting in the way.
3. Automation of knowledge work
If LLMs continue to become more powerful, they will automate a significant portion of knowledge work, which includes LLM assisted work. As a result, knowledge work will become a commodity, and skills that don’t require an LLM will become more valuable.
The paper mathematically analyzes how information can be effectively spread over a dynamic network while dealing with attempts to stop the information spread. It comes to the conclusion that randomly broadcasting information improves the speed of information spread in worst case scenarios.
I think the fact that randomly broadcasting information improves worst case scenarios is a very useful fact to remember. Often, spreading information more quickly is better. Also, a strategy of randomly broadcasting information takes less time.
I don’t currently use LLMs to code. However, I see value in taking things learned from an LLM coding tool such as Claude Code, and building something that is more useful.
I’ve tried using LLMs to generate code as a way of understanding their capabilities. I think they do a great job of generating technically correct code that provides short term value. However, I don’t think they are effective at generating a UI because the quality is subjective based on user preferences.
However, I don’t think they are at the point where they are reliable enough to be used for a medium to large codebase without human review.
When thinking about using LLMs or some other AI tool to generate code, here are two things I am looking for.
Output quality can be objectively defined by a numerical value.
Code output that does not have to be manually reviewed by a person.
With these two criteria in mind, I think the workflow of using LLM tools to write code and then manually reviewing the code is not effective.
First of all, information overload is a major challenge right now. Having to review additional code adds to the overload. LLMs can also generate code at a very fast pace, and reviewing additional code adds to the overload.
Also manually reviewing LLM generated code may not be useful. People including myself do not enjoy doing code reviews. Getting code change requests reviewed was a consistent problem for developers at the past several tech jobs I had. I have also seen open source projects where there were dozens or even hundreds of change requests waiting to be reviewed. Some of them were open for more than a year.
Also, source code quality isn’t an entirely objective measurement. It is true that source code determines of a program runs without bugs. However, source code also has subjective measurements. Different people can format code in different ways because of preferences, and equivalent logic can be implemented in multiple ways.
If an AI tool is being used to write code, I think it is best for someone to look at the user-facing output and not pay attention to the generated code. In this case, an effective AI tool would save time and reduce the amount of information someone has to process. If an LLM is used to generate code.
I think vibe coding is a better path forward. It doesn’t address the challenges with UI output not being objectively measurable and large codebases are probably going to be a challenge. However, I think it is an improvement over generating code with an LLM and reviewing it.
Coding is a key part of product development. However, it is only a small part. Significantly more time needs to be spend on activities such talking to potential users, figuring out what to build, testing, and getting user feedback. Also, organizations create many products that do not involve writing software. It’s important to realize that software is a tool that is suitable for solving certain problems.
As an example, for Create Third Places, I have been spending a significant time learning about urban planning concepts that are related to third places, and this does not require creating software. Even for dmvboardgames.com, which is a software project, I am not spending a significant amount of time coding. More of my time is spent on talking to users and thinking about ways to improve the user interface.
I think previous experience also affects how much a tool should be used. My previous software experience is helping to make coding useful for Create Third Places. On the other hand, Create Third Places could function without me creating software if I had a different set of skills.
Due to the fact that coding speed is only a small part of an organization, one should be careful about focusing too much on coding speed. After a certain point, efforts to improve coding speed can have a negative impact because less time is spent addressing the bottlenecks.
Time spent to address bottlenecks besides coding will be more important. Also, addressing bottlenecks will involve set of skills, and practicing a skill will make you better at it. In the long run, this will mean less time is necessary to address bottlenecks.
Over the past decade, I’ve also noticed that software development requires a mindset that is very different from other work. I find that I can have a balanced software mindset if I minimize unnecessary coding. However, if I focus too much on coding while trying to improve speed, I start to have difficultly with other work. I think one reason is the fact that I see software as rooted in real world use, and unnecessary coding disconnects me from the real world.
For further information, I recommend the Deep Life Podcast by Cal Newport. Cal is a computer scientist who talks about the impact of technology and ways to manage information overload.
Currently, I see information overload as a challenge for society, and I want https://createthirdplaces.org/ to help address the challenge.
Create Third Places does not have an official presence on any social media website right now. While I could theoretically reach more people with social media, I don’t see that as beneficial. I would be competing with large organizations with vast amounts of resources to spend on social media that will probably make Create Third Places hard to notice.
Social media websites already present people with a large amount of information that causes overload. As a result, details about Create Third Places could be missed or understood incorrectly. I would also be adding to the amount of information overload people are dealing with. In addition, I would have less time to spend on other work because of the effort necessary to make Create Third Places visible on social media.
By sharing information about Create Third Places without social media, I am encouraging slower paced information gathering that prevents an overload. It is easier to share information Create Third Places in person where the environment is less distracting.
The amount of information we are generating is rapidly increasing and information can be shared with more people through social media. However, the amount of information we generate is outpacing our ability to process it, which is causing challenges. This decline is demonstrated by a study showing that attention span when using computer declined from 3 minutes in 2004 to 40 seconds in 2023.
For the purposes of this article, I am classifying information as something that people are paying attention to and thinking about. For example, computer code that someone types is information. However, if the code is compiled into machine readable code, I don’t consider it information since a person will not be looking at. Automatically generated text is not information if nobody is going to pay attention to it. By the same logic, a busy city sidewalk may not cause information overload if you aren’t paying close attention to details about your surrounding that aren’t relevant to walking.
Challenges with information overload
Human brains have a limited capacity to process information. The extra information tends to become a net negative. More information means you are receiving information more rapidly. This means more context switching from trying to process information to trying to receive information. The information may also accumulate in your brain, causing an ongoing cost.
Context switching also has a time cost. Also, if you are context switching when trying to process information, unprocessed information will sit in your brain. Even if the time cost of context switching was hypothetically zero, information overload has a significant cost.
To simulate the effects of context switching, I set up a simulation representing 1 hour of time where it took 60 seconds to process a unit of information. I then configured 60 units of information to come at random intervals. Across 10,000 runs with 2 seconds of context switching to handle interrupting information, an average of 52.6 units of information were fully processed. If the number of units of information was doubled to 120, an average of 54.5 units of information was processed due to less downtime.
If the time needed to handle interrupting information increases, then the ability to process information will be significantly lower. At a certain point, the ability to process information will be close to 0.
Here are the results from running the simulation with different interruption lengths.
Interrupt time
Information processed with 60 incoming units
Information processed with 120 incoming units
2 seconds
52.6
54.5
4 seconds
51.3
46.9
8 seconds
48.2
43.1
10 seconds
46.5
39.3
1 minute
5
0.6
2 minutes
0.9
0.2
23 minutes
0.6
0.1
These figures are likely underestimates due to the cognitive load of trying to keep information in your head until later, forgetting something, and some interruptions requiring switching priorities.
For example, let’s say you received 10% more information in an hour than you could process. More than 10% of the information you receive will be unprocessed. In the real world, the 10% of extra information will be spread out over the hour instead of being concentrated at one time period. In a scenario where you prioritize completing processing of a piece of information before moving on, some of your mental capacity will be devoted to prioritizing the 10% of information that you cannot currently process.
Challenges with information overload suggest that we should be careful about tools that allow us to generate output more quickly. This reduces the cost of generating output, which is an incentive that can cause people to generate more output. If people are looking at that output, that means adding to the information overload problem.
However, this doesn’t mean completely getting rid of tools that help you generate more informational output. Used with intention, they can be helpful. For example, when creating pages for this website, I did not log into the server and manually upload a file with HTML website markup. Instead, I used the WordPress content management system(CMS) I set up to type the page content and click the “save” button. The automatically generated HTML code is not extra information since I do not need to look at it.
The WordPress CMS on this website includes a large volume of code. However, it is not adding to the amount of information I need to process. The configuration I set up over a decade ago still works today, and I have never had a reason to look at the CMS server code.
Solutions
While technology can contribute to this issue, I think it is important to avoid the trap of focusing too much on problems with specific technologies. Technologies with positive real-world impact are contributing factors with the Internet being one example. With the Internet, it is important to remember how useful it has been to connect with people and find essential information.
The Internet can also be a useful tool for reducing information overload. For example, using an online tool for research can mean spending less time looking at irrelevant information from manually going through sites.
Back in 2012, I took a computer science course where the professor talked about an equivalent problem with computer memory. The fact that I remember the professor and the course demonstrates the value of focus and not taking in too much information. I was paying attention during the lecture and did not attempt to learn the material by skimming through a textbook while doing something else.
I have been spending more time on lower information activities when a higher information activity doesn’t provide much of a benefit. For example, yesterday I was doing research on population statistics in Arlington County, Virginia during the 1960s and 1970s. I decided to take the extra time to go to a library to look up the information. If I tried to look for the information on the Internet, I probably would have stumbled upon a lot of information that would have difficult to fully process.
At the library, I found information by reading old printed reports from Arlington County. The extra information was relevant to me, since the research was for an article about how neighborhoods in Arlington developed differently. I also took notes with a pen and paper instead of using my laptop. This made it harder to get distracted by the Internet since I would have to take the additional steps of unlocking my phone and opening a web browser.
Recently, the DC Metro has enabled Automatic Train Operation, and it has been great as a rider. Train rides seem to be significantly smoother and quicker. From an engineering perspective, I think this is a great form of AI in the form of domain specific automation. Trains are running based on clearly defined parameters and success criteria.
When riding the bus yesterday, I was also impressed with the new domain specific automation shown in the picture below. It took the GPS position of the bus and showed the upcoming stops.
This week, I have also been appreciating the automated weather forecast models telling about the upcoming heat wave.
Also, I leveraged a domain specific automation to make this blog post. I did not write this post in HTML and manually upload it to a server. Instead, I logged into the WordPress CMS and typed content using a visual builder tool. Once I clicked the save button, the changes went live.
I was considering adding a corkboard texture to event information on dmvboardgames.com to look more like a physical bulletin board for usability purposes. At first, I saw it as a good way to emphasize the site’s focus on in-person events. The next day, I thought about the idea some more and decided that it wasn’t a good idea.
I came to the conclusion that adding a corkboard texture was not a good use of time for the following reasons.
User feedback I received in the past does not give a clear indication that a corkboard texture would improve usability. On the other hand, a corkboard texture could negatively affect usability by adding additional content.
The main goal of the site is to show information about in person board game events in the DC area, and a bulletin board doesn’t clearly help. Other elements besides text have a clear purpose. The hex background is supposed to be a reference to hexes in board games, and I use colors that resemble hexes in the board game Catan. The figures at the top are meeples, which are commonly used in newer board games. The different colors are to promote inclusivity in board games.
Additional styling will have an ongoing cost in maintenance.
The boundaries between in person events and websites would be blurred. I want the site to exist as an entity distinct from the events themselves.
I then thought about my earlier views towards adding a corkboard texture as a way of trying to improve the usability of the site. Then I decided to think more about user feedback I had received to make some smaller UI improvements.